
What issue can we solve for you?
Type in your prompt above or try one of these suggestions
Suggested Prompt


Insight
The Race to Faster and Cost-Efficient LLM Training: Trends, Techniques and AWS Innovations
The Race to Faster and Cost-Efficient LLM Training: Trends, Techniques and AWS Innovations

Large Language Models (LLMs) have revolutionized the AI landscape; however, their training process remains a significant challenge due to high costs and resource-intensive requirements. DeepSeek’s breakthrough with its R1 model, which claims to achieve a 95% reduction in training costs, offers an early glimpse into the future of low-cost, faster LLM training. LLM creators and tech companies are investing heavily in innovative solutions to reduce the time, financial costs, and environmental impact of training these models.
This post explores advancements in the industry and outlines primary approaches for customers leveraging LLMs across a set of scenarios.
The key advancements here are around the following approaches:
- Hardware Innovations involving tweaking and streamlining of the training hardware, such as custom chips from Microsoft.
- Software optimization techniques with a focus on getting better training performance with existing hardware by ensuring effective memory utilization. Techniques such as Mixed precision training and Activation checkpointing have proven to be effective in this category.
- Distributed model training by either leveraging multiple GPUs in parallel to train and/or using data parallelism technique designed to optimize memory usage and scalability during the LLM training by leveraging libraries such as FSDP
- Optimized training frameworks such as Fast-LLM from ServiceNow, an open-source library developed for training models of all sizes employs a mix of the above techniques (mixed-precision, distributed training and hardware optimizations) to maximize throughput and minimize training time.
- In scenarios where a smaller model is a better fit, techniques like Knowledge distillation, where a smaller "student" model is trained to replicate the performance of a larger "teacher" model, can be effective. This allows the student model to benefit from the teacher's knowledge without the extensive computational resources required to train the larger model from scratch.
- Shift from traditional supervised fine-tuning (SFT) to reinforcement learning (RL)-first approach as used for DeepSeek-R1. Most large language models (LLMs) begin their training with supervised fine-tuning (SFT) to establish foundational knowledge. However, DeepSeek-R1-Zero deviated from this traditional approach by skipping the SFT stage entirely. Instead, it was trained exclusively using reinforcement learning (RL), allowing the model to independently develop advanced reasoning capabilities, such as chain-of-thought (CoT) reasoning. This innovative RL-first strategy enabled the model to explore and refine its reasoning processes without relying on pre-labeled data.
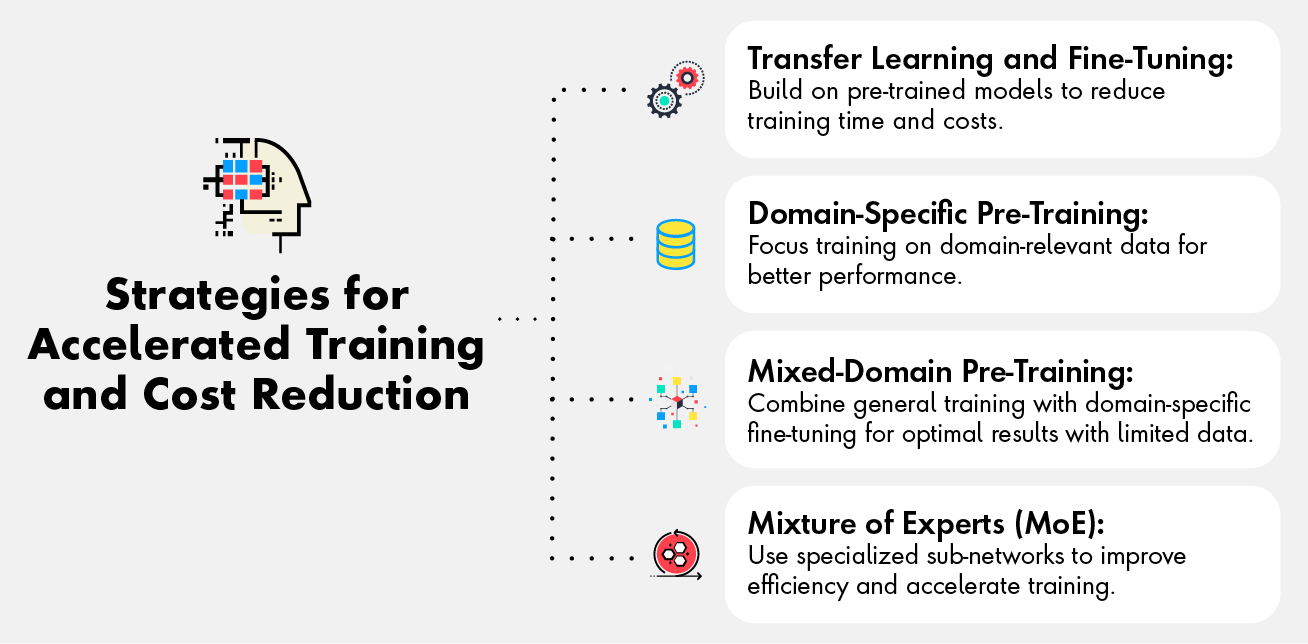
Organizations looking to leverage LLMs (Large Language Models) for specific domains or use cases should adopt one or more of the following strategies to accelerate training and reduce costs:
- Transfer learning and Fine-tuning – this involves starting with a pre-trained model and fine-tuning on domain-specific data. By leveraging pre-trained models and knowledge from existing tasks, transfer learning significantly reduces training time, data requirements, and computational costs.
- Domain-specific Pre-training – in this approach, a relatively smaller model is pre-trained specifically on domain-relevant data rather than undergoing general pre-training. This method can lead to better performance in the target domain compared to general pre-training followed by fine-tuning. However, this approach requires sufficient domain-specific data to be effective. A potential solution to this challenge is using smaller, specialized LLMs that perform well on tasks within a specific domain while disregarding performance in unrelated domains. Small models benefit from comparatively fast inference times, lower latency, and less expensive training. Their reasonably small size allows them to be hosted on local, consumer-grade hardware.
- Mixed-Domain Pre-Training is an effective strategy when there is insufficient domain-specific data for the model to develop a strong understanding of natural language. In such cases, the model can first be pre-trained on a large general dataset to learn foundational language patterns and then fine-tuned on the smaller in-domain dataset. This approach typically yields better performance compared to training solely on a limited domain-specific dataset.
- Another efficient method for domain-specific modeling is the Mixture of Experts (MoE) approach. MoE divides the training workload across multiple specialized sub-networks, activating only the relevant sub-networks for specific tasks. This not only improves efficiency but also accelerates training times by optimizing resource utilization.
Depending on the use case and available resources, research suggests that domain-specific and mixed-domain pre-training can be a viable and preferable alternative to general pre-training. Referencing here a great piece of research done for medical use case to compare and benchmark different approaches.
AWS innovations are transforming LLM training, enabling faster, cost-effective solutions that empower businesses to stay ahead in the AI revolution.
AWS with its global scale across industries, is innovating rapidly across the above areas and have industry leading capabilities. AWS has many capabilities to offer across generic training, continued pre-training, fine-tuning and domain-specific training. Listing down a few key ones here for GenAI application creators/engineers to explore:
- Amazon SageMaker provides managed training capabilities, enabling users to scale workloads efficiently without the need to manage infrastructure. Features like Amazon SageMaker HyperPod allow users to train foundation models at scale with thousands of accelerators, reducing training time while ensuring resiliency and automated recovery from failures.
- Additionally, Amazon SageMaker Model Training supports Activation checkpointing and distributed training libraries that automatically split large datasets and models across GPUs, simplifying the process for developers.
- The Amazon EC2 P5 instances deliver up to 6x faster training times compared to previous generations. These instances also support FP8 precision, which boosts performance by up to 18%, making them ideal for cost-effective LLM training.
- For domain-specific use cases, AWS provides curated model libraries and recipes through Amazon SageMaker HyperPod, allowing customers to fine-tune popular models like Llama or Mistral in minutes.
- For orchestration at scale, AWS Trainium, integrated with AWS Batch, offers massive scalability and cost efficiency. This combination allows users to train models across tens of thousands of accelerators while simplifying job scheduling and resource management.
Together, these tools empower organizations to train LLMs faster, more efficiently, and at a lower cost, enabling innovation across diverse domains.

Related Reading
-
![]()
Building Large Language Model Operations (LLMOps) on AWS Technology Stack
How to deploy Gen AI solutions at scale without spending excessive time and money assembling tools and solutions from various vendors.
-
![]()
Generative AI with Publicis Sapient and AWS
Embrace a new era within your organization by leveraging generative AI. Publicis Sapient’s partnership with AWS simplifies navigation through the generative AI landscape.
-
![]()
AskBodhi: Deploying Generative AI at Scale
AskBodhi on AWS Cloud technology is our groundbreaking solution to power Generative AI and enable you to deploy use cases in a matter of days or weeks.


